
Why Data Warehouse Projects fail?
If the subject line attracted you here, let me calm you down, not all data warehouse (DWH) projects fail. Some are indeed successful and vital for organization‘s long-term strategy and vision. Nevertheless, a lot of projects, which come under DWH umbrella, do fall short. Lets investigate why.
Data lake vs. Data Warehouse vs. Data Mart?
Data Warehouses have been around for as long as I remember. There was always a search for the best ways for organizing and optimizing data. Classic solution has been SQL database. As data has seen increase in variety and volume, but decrease in quality, it became quite apparent that Data Warehouse cannot be the only solution.
The premise of the Data Warehouse(DWH) is the schema definition, in simple terms you need to know the structure of the source data. As an implication of fixed schema definition, when the source structure changes, you need to apply change to the DWH and upstream. This posed significant problems for data ingestion. With number of systems a typical organization run increasing it became difficult to do the first step — extraction. In order to make a clear split between extracting and cleaning data, the term Data lake was coined. For a data lake the goal is collect all data in one place with minimal to no-concern for quality or business meaning of it. DWH contains business logic embedded in schema and stored procedure. DWH is the first place, where data makes sense.
On the other hand, the meaning of the data has to be kept very generic to fit multiple business units, also data has to be stored efficiently (normalized). To make data serve a particular use case of a single or multiple business units, a lot of linking and transformation is needed. In plain terms, queries to answer business questions will be very long and complex. To avoid this usually a Data Mart is created, with the purpose of having the data in form and quality to answer a particular business problem. The most common use case would be reporting.
To sum it up the purpose of each of these systems can be stated as:
- Data lake — collect data
- Data warehouse — structure data
- Data mart — understand data
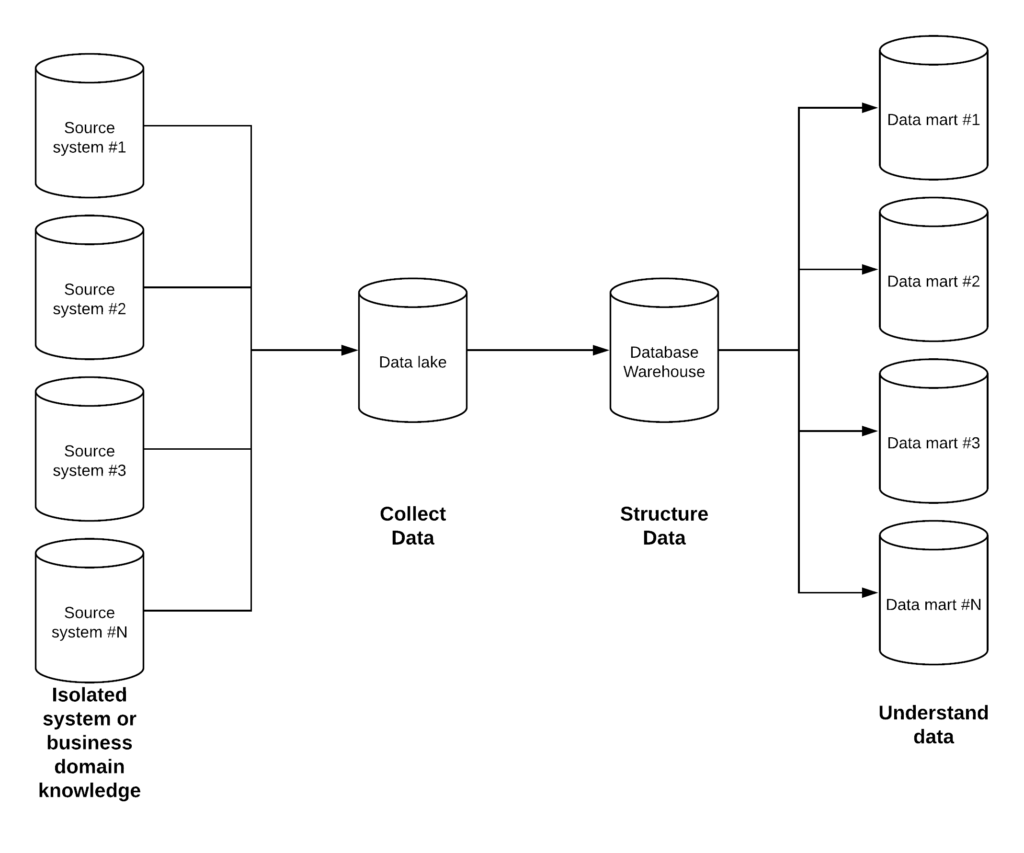
Purpose of Data lake, Data Warehouse, and Data mart
This is where the first failure comes into play. Organizations have hard time making clear distinction and start doing the usual “but” thing. For example, data lake is used for collecting the data, but can we also streamline it so we understand what it means? Data mart gives understanding of the data, but why do we need to run the whole process if our source system is very similar to what we need — lets just populate it directly. This leads to subtle problems — suddenly gaining insights from data becomes very time consuming and inconsistent riddled with errors.
A more apparent failure to distinguish purposes of data storages manifests in selection of technologies. Vendors are partially at fault, because they want to tap into different markets, but mostly it is inertia of individual teams and organization, which become very comfortable with one set of technologies and it becomes a hammer for every nail. Typical split would be:
- Data lake: NoSQL / file system (can be NTFS or hdfs)
- Data warehouse: SQL database
- Data mart: SQL Database
When IT team gets frisky with technology choices or business decides to go its own way this is what happens:
- Data lake: SQL database and try to ram whatever we get out source systems into it
- Data warehouse: Lets use NoSQL technologies, because actually they have some SQL complaint interfaces
- Data mart: IT says we have too many databases, so we will just export data as flat files and use them for reporting
The one particular case, where it costs organizations a lot, is in-memory databases. Somehow vendors made in-memory database option more prominent than it should be. There is nothing wrong putting minor amount of data from data mart into in-memory database. This would make slicing and dicing it very quick. When decision is actually to put entire DWH on top of in-memory database — it will cost you millions in hardware and license fees.
Now let’s talk about the root cause of all the problems.
Why we move the data?
There is always a question that I am dazzled nobody asks — “Why do we need to move the data in the first place?”. And here is where the truth comes out:
- Legacy systems. Notorious term for systems that run well, look horrible and nobody understands how they work. Legacy systems were often built as a monolith in mind and some of them are a strong monolith, which does the job they were built for well. The problem is the only (automatic) way to get the data from a monolith is through the backend database. This is where the hell breaks loose, because the real name for the process is “reverse engineering”. Nobody knows exactly the logic, so the only thing you can really hope to get out of it is a raw data. If you get schema — consider yourself lucky, if you get documentation on backend system — quit and go straight to casino
- Making new business logic and actually a new system. When business comes with new requirements, which for several reasons cannot be implemented in the system, where it belongs, a new component is created to compensate for that. Reasons might include: it is a third party application; changes in the system are too complex and time consuming to implement, we don’t touch a running system, it is another team and we don’t want to talk to those guys
- Analytics. It is not clear, who started it first — database engineers or data scientists, but the process is clear — get all data in one place, preferably in one table, and statistical models will be built on top of this. And if you can provide it as a CSV file — bonus points for that. For example, the most popular programming language for data science — R, and the ecosystem around that subtly has ETL process in mind. Yes, there are different DB connectors and libraries even for building REST clients and servers, but be honest — wrangling with DB access and service endpoints is not your dream way of getting the data into R.
Core banking systems, collective term used for all application, which make money moving. Quite often they are so complex, that instead of naming components, the whole process name is used, e.g. cash deposits and withdrawals, transfer processing, balances and limits, and etc. This is a perfect example, when data dumps are done to get data and try to use it across the whole organization.
So, you proceed to drag data throughout the organization, some of it will die on the way, some units carrying it will collapse, but you carry on with the deadly stride to destination, because this is the only path you know. I refer to the process of dragging data through organization without purpose and/or by wrong means — a plague caravan.
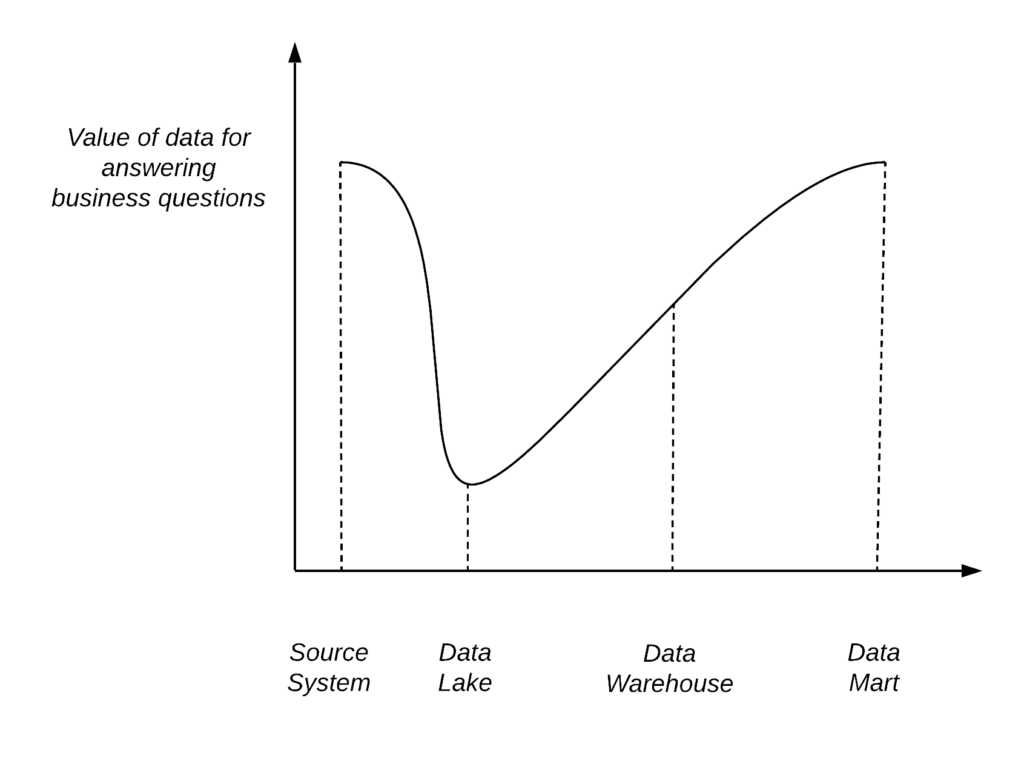
Plague caravan. Moving data through the classical process
Example
Let’s imagine a simplified situation — you have three systems and each one of them has just one table:
- CRM contains customer data, e.g. names, address, date of birth and etc.
- Transaction system of (core) banking system with transactions data
- Account management system, which contains information, which types of account exist (loan, deposit, checking) and which limits are assigned to each
This scenario is not that uncommon and sometimes even makes sense. For example, transactions need to happen instantaneously, while you don’t change your name every day.
Now imagine a scenario — you are tasked to display spending for today in the app across all accounts. Sounds simple, right? How would the code look for that? Database engineer’s answer:

Cool stuff, took one minute. Here comes the first catch though. In order to run such a query, you need to move several 100s GB of data from 3 databases into one place. So you proceed to do it. It generally works, except for Thursdays… On Thursdays you don’t get any data, you investigate and you realize that this is because one of the databases has maintenance window. No biggie — you move ETL schedule a bit down and here we go, all the magic works. You are happy, you provide the table or a view to the digital frontend teams and sail to the horizon with a successful DWH project.
One day later you receive an angry email, which can be summed up in one sentence — “You screwed this up”.
Too late
First thing that business starts noticing, customers sometimes don’t get data, i.e. your daily ELT job delivers data too late. Customers keep calling regarding incorrect balance — this causes call center do some overtime and incurs real costs. By the way, to add insult to injury, transactions are displayed in fact correctly, because they are taken directly from real-time transaction system. You switch ETL job to hourly, then 10-min interval. This causes quite some overhead on productive systems, but you just ordered some hardware and roll with it.
Data quality
Some weird thing happened. Business keeps telling that the balance is incorrect, and you are really puzzled, because you just need to sum things up… A guy from transaction system team shows up and casually mentions 777. You ask if it is a Fallout shelter number and he replies — no, this is a special code, which is used for corrections of things (he explains actually what, but you don’t get it anyways). So, he says that all transactions with type 777 must be excluded. Then he mentions around 30 other codes, that you should not use in calculation, that you proceed to frantically write down. Then a guy from accounting team shows up and explains that a bunch of the accounts are used for internal things (he also explained why, but you blackout at that moment as well)
So, you come back at your desk and rewrite the query, which now looks like this:
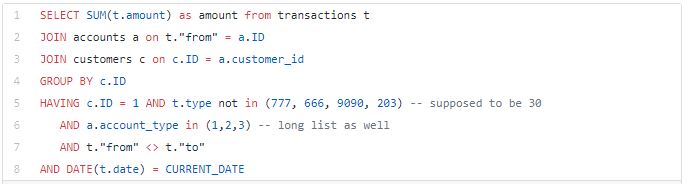
This looks much less clean. But you roll with it. Things seems to be working… for a week… Then call center starts reporting problems again. You investigate and find out that account management team has not informed you about new family account type added, which makes your query obsolete and you go back rewriting it.
In real life, the last paragraph becomes your pain for a very-very long time -.-
Alternatives
A strategic question that needs to be answered is do we bring data to the question or do we bring question to the data? The whole premise of DWH projects and plague caravan (Data lake -> DWH -> Data Mart) is that the business question can only be answered somewhere upstream and our only hope is to keep dragging it up and up. But is it the only option? Definitely not. There are three architectural ways to actually split the business problems and bring them to the data source:
- API Abstraction. If a system provides API that you can utilize — that is great, and you should definitely use it. There is no reason to use underlying database, when a developer of the system literally gave you a logic to use. API is something that is intended to be used externally. Database is for external use, so you are subscribing to be a mind reader. In case there is no API, you are left to your own devices. This is where it is important to distinguish different level of abstraction — system API and business logic API.
- GraphQL is an interesting case of API abstraction, where you are writing a generic system API (server) for one or more legacy systems and query them in the way that is most convenient for the client. GraphQL literally list legacy system abstraction as one of the use cases, which has been very underutilized in my opinion.
- Data pipelines. One approach, which has been emerging recently is replacing static scripts with structured and repeatable steps, which can be reused across multiple pipelines (defacto business questions). This is definitely a step up from SQL scripts approach; however, this approach is plagued right now by vendors trying to explain how business can replace IT with colorful drag and drop boxes.
A big advantage of these approaches is the utilization of legacy systems. If it is not clear for you still, remember, legacy systems are not going away today or tomorrow, so you have to learn to co-exist with them.
Every option above ensures that most important questions and definition is answered at the source. Stick around for practical how-to guides on each of these approaches.