
Vom Aus der Third-Party-Cookies: Alternativen zur Datengenerierung
Bereits zu Beginn des Jahres 2020 kündigte Google an, Third-Party-Cookies innerhalb des Google-eigenen Browsers Chrome abzuschaffen, auch wenn nun mit 2023 ein Jahr später als ursprünglich geplant. In der von Google veröffentlichten Stellungnahme heißt es: „Today, we’re making explicit that once third-party cookies are phased out, we will not build alternate identifiers to track individuals as they browse across the web, nor will we use them in our products.“
In diesem Artikel erfährst du, was das eigentlich genau bedeutet, welche Auswirkungen das auf die Gewinnung von Daten hat und welche Rolle Open Source Daten und sogenannte synthetische Daten in Zukunft einnehmen könnten.
First- versus Third-Party-Daten
Ab 2023 ist es soweit. Browser wie Safari und Firefox haben bereits einen gewissen Schutz gegen Tracking-Cookies von Drittanbietern implementiert, nun wird auch Google nachziehen und Third-Party-Cookies abschaffen. Um die tatsächlichen Auswirkungen davon greifbar machen zu können, ist zunächst einmal die Unterscheidung von Third-Party- zu First-Data und -Cookies hervorzuheben. First-Party-Data sind Daten, die das Unternehmen selbst erhebt. Beispielsweise erfassen Unternehmen mittels des Opt-In-Prozesses die Email-Adressen und gegebenenfalls Namen und Geschlecht der NutzerInnen. Third-Party-Data sind hingegen Daten, welche von externen Firmen über NutzerInnen gesammelt werden, die in keiner direkten Beziehung zueinander stehen. Das Ziel ist es, Informationen wie Demografie, Interessen oder Kaufabsicht zu sammeln.
First-Party-Cookies werden direkt vom Website Publisher am Server oder durch ein JavaScript auf der Website gesetzt. Sie werden also vom Betreiber erzeugt und als Textdatei gespeichert und dienen dazu Websiteeinstellungen, Meta- und personenbezogene -Daten über Webformulare zu sammeln. Für eine optimale Nutzerfreundlichkeit lohnt es sich diese im Cookie Banner zu akzeptieren. Hingegen werden Third-Party-Cookies von Dritten (wie Werbevermarktern und anderen Online-Werbedienstleistern) auf Fremdanbieterseiten gesetzt. Wenn jemand also Werbeanzeigen von Werbetreibenden sieht oder klickt, wird neben dem First-Party-Cookie ein weiterer Third-Party-Cookie gesetzt. Somit kann Website-übergreifend das Nutzerverhalten nachvollzogen und im Bereich des Targetings für Online Marketing Maßnahmen verwertet werden.
Nachdem immer mehr User Third-Party-Cookies blockieren, haben sich die Firmen rund um die meistgenutzten Browser nun dazu entschlossen, diese endgültig zu verbannen. Dies bedeutet natürlich eine große Umstellung für Third-Party-Anbieter und fordert neue Lösungswege, um Nutzerverhalten messbar zu machen. Ein Ansatz, den beispielsweise Facebook mit dem Facebook-Pixel oder auch Salesforce mit Pardot verfolgt, ist die Umstellung des Third-Party zu einem First-Party-Cookie. Das Prinzip entspricht einer Simulierung eines First-Party-Cookie – der Cookie sieht also für den Browser so aus, als käme er von der Website welcher der Nutzer selbst aufgerufen hat. Auf der Website muss lediglich eine Facebook-Werbung oder auch ein Pardot-Tracking Code gesetzt sein. Der Cookie sendet im nächsten Schritt die Daten an den externen Anbieter und führt weiterhin die Funktion eines Third-Party-Cookie aus. Um auch hier weiterhin GDPR-konform zu bleiben, muss allerdings die Cookie Information auf der Website im Banner und auf einer Datenschutzseite angepasst werden und dem NutzerInnen jederzeit die Möglichkeit eines Widerspruchs hinsichtlich der Daten-speicherung und -Verwendung, durch andere Anbieter, geben.
Das Potenzial von Open Source und synthetischen Daten
Für Unternehmen bedeutet diese Umstellung sich auf eigene, First-Party-Daten zu fokussieren und Möglichkeiten zu nutzen, die gesetzeskonform sind. Müssen Daten von Dritten zugekauft werden, um beispielsweise die vorhandenen Daten mit fehlenden oder einfach nur zusätzlichen Daten anzureichern, muss nun auf Alternativen zurückgegriffen werden. In diesem Zusammenhang können sogenannte Open Source Daten und synthetische Daten eine bedeutende Rolle einnehmen.
Open Source Daten
Open Source Daten sind Daten, die grundsätzlich frei genutzt, weiterverwendet und geteilt werden können und somit keinen rechtlichen, technischen oder sonstigen Kontrollmechanismen unterliegen. Laut dem European Open Data Maturity Report 2020 können folgende Trends in Bezug auf offene Daten genannt werden:
- Die COVID-19-Pandemie hat den realen Bedarf an Daten deutlich hervorgehoben
- Der Reifegrad der Datenqualität von Open Source Data ist ansteigend (von Quantität zu Qualität von Daten)
Sieben Länder konnten in der Studie als Trendsetter in Europa identifiziert werden, darunter zum ersten Mal auch Österreich. Namenhafte Open Source Datenbanken sind beispielsweise Statistik Austria oder Eurostat auf europäischer Ebene.
Aktuell untersucht Deloitte als Vertragspartner der Europäischen Kommission in einer Studie hochwertige Datensätzen (HVD) im Rahmen der Open Data Richtlinie (EU) 2019/1024. Ziele der Studie sind die Befüllung der einzelnen Datenkategorien mit konkreten Vorschlägen von Datensätzen und eine Darstellung der wirtschaftlichen und gesellschaftlichen Potentiale der Verfügbarmachung von HVD.
Synthetische Daten
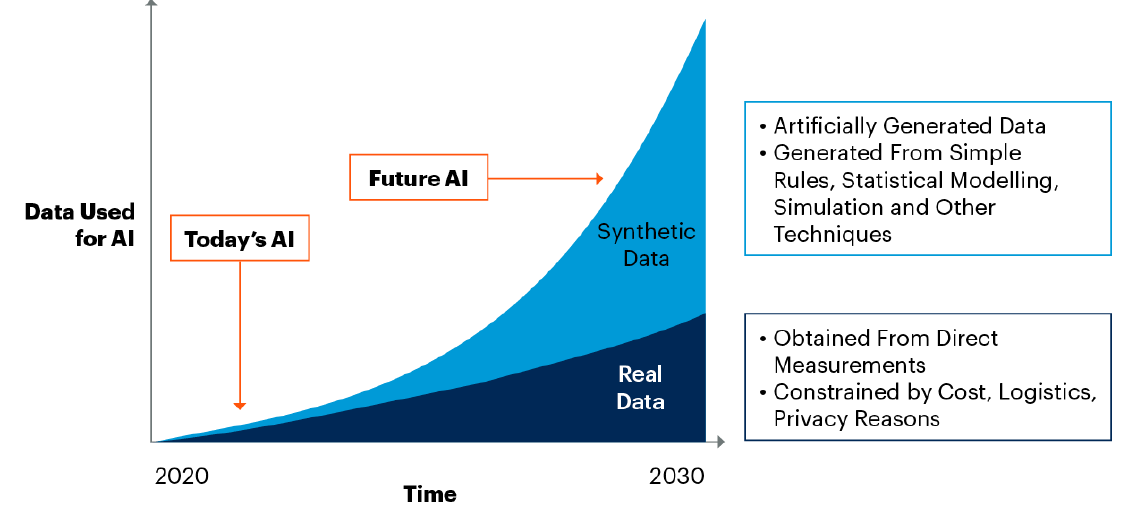
Synthetische Daten sind eine Klasse von Daten, die künstlich erzeugt werden. Tools zur Generierung synthetischer Daten erzeugen Daten, die mit den Sample-Daten übereinstimmen und stellen gleichzeitig sicher, dass die wichtigen statistischen Eigenschaften der Sample-Daten in den synthetischen Daten wiedergegeben werden. Sie werden oft als „minderwertiger“ Ersatz angesehen, die nur dann nützlich sind, wenn reale Daten nur schwer oder gar nicht zu beschaffen, teuer oder durch Vorschriften eingeschränkt sind. Jedoch steckt weitaus mehr Potenzial in synthetischen Daten. Ohne synthetische Daten wird es in Zukunft kaum möglich sein, qualitativ hochwertige Künstliche Intelligenz (KI) -Modelle erstellen zu können. Beruft man sich auf Erick Brethenoux, dem Leiter der KI-Forschung bei Gartner, werden bis 2024 etwa 60 % der Daten, die für die Entwicklung von KI- und Analytics-Projekten verwendet werden, synthetisch erzeugt sein.
Fazit
Um die Folgen der immer strengeren Regulierungen der Privatsphäre im Web, wie die Abschaffung von Third-Party-Cookies zu umgehen, bieten Open Source und synthetische Daten eine optimale Lösung. Mittels KI-Berechnungen können synthetische Audiences gebildet werden, welche aus den historischen Daten lernen und Profile mit neuem Webverhalten anreichern. Mit Data Analytics-Tools wie Tableau, Tableau CRM oder auch Datorama von Salesforce können Zielgruppen letztendlich noch weiter geschärft werden, um ein optimales Targeting umsetzen zu können. Benötigst du Hilfe bei der Lösung dieser Problematik oder möchtest einfach nur weitere Informationen zu diesem Thema bekommen, dann melde dich gerne bei uns für ein kostenloses Beratungsgespräch!

Manager
MarTech & Data Analytics